

四大函数式接口
Supplier 供给型接口
无参数,返回一个结果。
示例:
Supplier<String> supplier = () -> "Hello";
Consumer 消费型接口
接受一个参数,无返回结果。
示例:
Consumer<String> consumer = (str) -> System.out.println(str);
Function 函数式接口
接受一个参数,返回一个结果。
示例:
Function<Integer, String> function = (num) -> "The number is: " + num;
Predicate 断定型接口
接受一个参数,返回一个布尔值结果。
示例:
Predicate<Integer> predicate = (num) -> num > 0;
这些函数式接口在函数式编程中起着重要作用,可以简化代码并提高代码的可读性。
四大函数式接口代码示例
1. supplider 供给型接口
原始写法:
Supplier<String> supplier = new Supplier<String>() {
@Override
public String get() {
return "Hello";
}
};
Lambda表达式写法:
Supplier<String> supplier = () -> "Hello";
2. Consumer 消费型接口
原始写法:
Consumer<String> consumer = new Consumer<String>() { @Override public void accept(String str) { System.out.println(str); } };Lambda表达式写法:
Consumer<String> consumer = (str) -> System.out.println(str);
3. Function 函数式接口
原始写法:
Function<Integer, String> function = new Function<Integer, String>() { @Override public String apply(Integer num) { return "The number is: " + num; } };Lambda表达式写法:
Function<Integer, String> function = (num) -> "The number is: " + num;
4. Predicate 断定型接口
原始写法:
Predicate<Integer> predicate = new Predicate<Integer>() { @Override public boolean test(Integer num) { return num > 0; } };Lambda表达式写法:
Predicate<Integer> predicate = (num) -> num > 0;
流式计算
流式计算是指使用流式 API 对集合进行操作和处理的编程方式。流式计算可以通过一系列的操作(如过滤、映射、排序、归约等)来处理集合中的元素,而不需要显式地使用循环语句。流式计算的核心是流(Stream),它是一个数据元素序列,可以进行各种操作来处理数据。
流式计算的特点
链式操作:流式计算支持链式操作,可以将多个操作连接在一起,形成一个操作流水线。
惰性求值:流式计算通常采用惰性求值的方式,只有在终结操作被调用时才会执行中间操作,这样可以提高效率。
并行处理:流式计算可以很方便地进行并行处理,提高处理效率。
流式计算的基本操作
中间操作:中间操作用于对流中的元素进行处理,例如过滤、映射、排序等。
终结操作:终结操作用于触发流的处理,产生最终的结果,例如收集结果、计数、归约等。
流式计算的示例
List<String> list = Arrays.asList("apple", "banana", "orange", "pear", "grape");
// 过滤出长度大于5的水果,并转换为大写形式
List<String> result = list.stream()
.filter(fruit -> fruit.length() > 5)
.map(String::toUpperCase)
.collect(Collectors.toList());
在这个示例中,我们首先将集合转换为流,然后进行过滤和映射操作,最后使用终结操作 collect 将结果收集到一个新的集合中。
流式计算可以使代码更加简洁、易读,并且可以充分利用多核处理器的优势进行并行处理,是现代 Java 编程中非常重要的一部分。
流式计算的常用中间操作
filter 过滤操作
用于筛选流中满足指定条件的元素。
示例:
stream.filter(x -> x > 5)
map 映射操作
用于对流中的每个元素进行映射转换。
示例:
stream.map(x -> x * 2)
sorted 排序操作
用于对流中的元素进行排序。
示例:
stream.sorted()
distinct 去重操作
用于去除流中重复的元素。
示例:
stream.distinct()
流式计算的常用终结操作
collect 收集操作
用于将流中的元素收集到集合或其他数据结构中。
示例:
stream.collect(Collectors.toList())
count 计数操作
用于统计流中元素的个数。
示例:
stream.count()
reduce 归约操作
用于将流中的元素进行归约操作,得到一个最终的结果。
示例:
stream.reduce(0, (x, y) -> x + y)
forEach 遍历操作
用于对流中的每个元素执行指定操作。
示例:
stream.forEach(System.out::println)
流式计算的中间操作和终结操作可以根据实际需求灵活组合,使得代码更加简洁和易读。同时,流式计算还支持并行处理,可以充分利用多核处理器的优势,提高处理效率。
public class stream {
//流式计算
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
list.stream()
.filter(x -> x % 2 == 0)
.map(x -> x * 2)
.sorted(Integer::compareTo)
.limit(2)
.forEach(System.out::println);
}
}ForkJoin
Fork/Join 框架是 Java 中用于并行计算的框架,它基于分治策略,将大任务拆分成小任务并行执行,然后将结果合并得到最终结果。Fork/Join 框架主要用于解决递归或者分治算法中的任务,并行执行这些任务可以提高程序的性能。
Fork/Join 框架的核心概念包括:
Fork(分解):将一个大任务拆分成若干个小任务并行执行。
Join(合并):将多个小任务的结果合并得到最终结果。
Work-Stealing(工作窃取):当某个线程完成了自己的任务后,可以从其他线程的任务队列中窃取任务执行,以提高整体的并行效率。
Fork/Join 框架的核心类包括:
ForkJoinPool:线程池,用于管理 Fork/Join 框架中的工作线程。
ForkJoinTask:表示 Fork/Join 框架中的任务,通常是一个抽象类,可以通过继承它来实现具体的任务。
RecursiveTask:表示可以返回结果的任务,通常用于递归任务。
RecursiveAction:表示不需要返回结果的任务,通常用于执行一些操作而不需要返回结果的情况。
Fork/Join 框架的使用步骤包括:
创建 ForkJoinPool:创建一个 ForkJoinPool 对象,用于管理 Fork/Join 框架中的工作线程。
创建 ForkJoinTask:创建一个继承自 RecursiveTask 或 RecursiveAction 的任务,实现 compute 方法来定义任务的执行逻辑。
提交任务:将任务提交给 ForkJoinPool 执行。
获取结果:如果任务是一个 RecursiveTask,可以通过 get 方法获取任务的执行结果。
下面是一个使用 Fork/Join 框架计算斐波那契数列的示例:
import sun.text.resources.FormatData;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.ForkJoinPool;
public class FibonacciTask extends RecursiveTask<Long> {
private Long start;
private Long end;
private Long temp=1000000L;
public FibonacciTask(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
if(end - start <= temp)
{
long result = 0;
for(Long i=start;i<=end;i++)
{
result += i;
}
return result;
}
else
{
Long mid = (start + end) / 2;
FibonacciTask left = new FibonacciTask(start, mid);
left.fork();
FibonacciTask right = new FibonacciTask(mid + 1, end);
right.fork();
return left.join() + right.join();
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println(System.currentTimeMillis());
Long i;
Long result = 0L;
for (i = 0L; i <= 1000000000L; i++)
{
result=i+result;
}
System.out.println(result);
System.out.println(System.currentTimeMillis());
ForkJoinPool pool = new ForkJoinPool();
FibonacciTask task = new FibonacciTask(0L,1000000000L);
System.out.println(pool.invoke(task));
System.out.println(System.currentTimeMillis());
}
}
在这个示例中,我们创建了一个 FibonacciTask 继承自 RecursiveTask,实现了 Fibonacci 数列的计算逻辑。然后通过 ForkJoinPool 提交任务并获取结果。
Fork/Join 框架通过分解任务、并行执行和合并结果的方式,可以充分利用多核处理器的优势,提高程序的性能。同时,Fork/Join 框架的工作窃取机制可以提高并行效率,使得任务能够更加均衡地分配到各个工作线程上。
异步回调
在 Java 中,实现异步回调的方法有多种方式,下面介绍两种常用的方法:
使用回调接口
首先定义一个回调接口,该接口包含一个回调方法,用于处理异步操作的结果。然后在异步操作中,将回调接口作为参数传递给异步方法,在异步操作完成后调用回调方法处理结果。
示例代码如下:
public interface Callback { void onComplete(String result); } public class AsyncOperation { public void doAsyncOperation(Callback callback) { // 异步操作的逻辑 // 完成后调用回调方法 callback.onComplete("Async operation completed"); } } public class Main { public static void main(String[] args) { AsyncOperation asyncOperation = new AsyncOperation(); asyncOperation.doAsyncOperation(new Callback() { @Override public void onComplete(String result) { System.out.println("Async operation result: " + result); } }); } }在上面的示例中,定义了一个回调接口
Callback,包含一个onComplete方法用于处理异步操作的结果。AsyncOperation类中的doAsyncOperation方法接受一个Callback对象作为参数,在异步操作完成后调用onComplete方法传递结果。在Main类中,创建了一个AsyncOperation对象,并通过匿名内部类实现了Callback接口,处理异步操作的结果。使用 CompletableFuture
Java 8 引入了 CompletableFuture 类,它提供了一种更方便的方式来处理异步操作和回调。可以通过 CompletableFuture 的方法链来定义异步操作,并使用
thenApply、thenAccept、thenRun等方法来处理异步操作的结果。示例代码如下:
import java.util.concurrent.CompletableFuture; public class AsyncOperation { public CompletableFuture<String> doAsyncOperation() { CompletableFuture<String> future = new CompletableFuture<>(); // 异步操作的逻辑 // 完成后调用 complete 方法设置结果 future.complete("Async operation completed"); return future; } } public class Main { public static void main(String[] args) { AsyncOperation asyncOperation = new AsyncOperation(); asyncOperation.doAsyncOperation() .thenAccept(result -> System.out.println("Async operation result: " + result)); } }在上面的示例中,
AsyncOperation类中的doAsyncOperation方法返回一个CompletableFuture对象。在异步操作的逻辑中,通过调用complete方法设置异步操作的结果。在Main类中,调用doAsyncOperation方法返回的CompletableFuture对象,并使用thenAccept方法处理异步操作的结果。
这两种方法都可以实现异步回调,具体选择哪种方法取决于实际需求和代码风格。使用回调接口可以更灵活地处理异步操作的结果,而使用 CompletableFuture 可以更方便地定义异步操作和处理结果。
CompletableFuture 类详解
CompletableFuture 是 Java 8 引入的一个类,提供了一种异步编程的方式,允许你在未来某个时间点完成某个任务,并在完成后处理结果。它支持非阻塞的异步编程,并且可以通过方法链来处理结果。
常用方法
1. 创建 CompletableFuture
CompletableFuture.supplyAsync(Supplier<U> supplier)
创建一个新的CompletableFuture,并在另一个线程中执行给定的Supplier。CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> { // 模拟耗时操作 return "Hello, World!"; });
2. 处理结果
thenApply(Function<? super T,? extends U> fn)
在CompletableFuture完成后,使用给定的函数处理结果,并返回一个新的CompletableFuture。future.thenApply(result -> result + " - Processed") .thenAccept(System.out::println);thenAccept(Consumer<? super T> action)
在CompletableFuture完成后,执行给定的操作,但不返回结果。future.thenAccept(result -> System.out.println("Result: " + result));thenRun(Runnable action)
在CompletableFuture完成后,执行给定的操作,不使用结果。future.thenRun(() -> System.out.println("Operation completed!"));
3. 处理异常
exceptionally(Function<Throwable, ? extends T> fn)
处理CompletableFuture中的异常,并返回一个新的结果。future.exceptionally(ex -> { System.out.println("Error: " + ex.getMessage()); return "Default Value"; });
4. 组合多个 CompletableFuture
thenCombine(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)
将两个CompletableFuture的结果组合在一起。CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> "Hello"); CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> "World"); future1.thenCombine(future2, (s1, s2) -> s1 + " " + s2) .thenAccept(System.out::println);
5. 等待多个 CompletableFuture
allOf(CompletableFuture<?>... cfs)
等待所有给定的CompletableFuture完成。CompletableFuture<Void> allOf = CompletableFuture.allOf(future1, future2); allOf.thenRun(() -> System.out.println("All tasks completed!"));
示例代码
以下是一个完整的示例,展示了如何使用 CompletableFuture 进行异步编程:
import java.util.concurrent.CompletableFuture;
public class CompletableFutureExample {
public static void main(String[] args) {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
// 模拟耗时操作
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Hello, World!";
});
future.thenApply(result -> result + " - Processed")
.thenAccept(System.out::println)
.exceptionally(ex -> {
System.out.println("Error: " + ex.getMessage());
return null;
});
// 等待所有任务完成
CompletableFuture<Void> allOf = CompletableFuture.allOf(future);
allOf.join(); // 阻塞主线程,直到所有任务完成
}
}
在这个示例中,我们创建了一个 CompletableFuture,模拟了一个耗时的操作,并在完成后处理结果。我们还展示了如何处理异常和等待多个任务的完成。
CompletableFuture 提供了强大的异步编程能力,使得代码更加简洁和易读,适合现代 Java 开发中的异步任务处理。
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class asyn {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Void> voidFuture = CompletableFuture.runAsync(() -> {
System.out.println(Thread.currentThread().getName());
});
voidFuture.get();
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
int i = 1/0;
System.out.println(Thread.currentThread().getName());
return "Hello";
});
future.whenComplete((t,u) ->
{
System.out.println("t :"+t); //正常返回结果
System.out.println("u :"+u); //异常信息
}).exceptionally(e ->
{
System.out.println(e.getMessage());
return "Error";
});
System.out.println(future.whenComplete((t,u) ->
{
System.out.println("t :"+t); //正常返回结果
System.out.println("u :"+u); //异常信息
}).exceptionally(e ->
{
System.out.println(e.getMessage());
return "Error";
}).get());
System.out.println(future.get());
}
}
JMM
Java内存模型(Java Memory Model,JMM)是一种抽象的概念,用于定义多线程程序如何与内存进行交互。JMM并不真实存在,它是一种规范,规定了程序中变量在内存中的访问方式。
JMM的核心概念
主内存与工作内存
主内存:所有变量都存储在主内存中,主内存是共享的。
工作内存:每个线程都有自己的工作内存,工作内存中保存了主内存中变量的副本。线程对变量的所有操作(读取、写入)都在工作内存中进行,最后再将结果同步回主内存。
内存可见性
JMM规定了线程对变量的读取和写入顺序,确保变量的修改在其他线程中可见。即,当一个线程修改了变量的值,其他线程最终能看到这个修改后的值。
JMM的三大特性:原子性、可见性、有序性。
原子性
一个或多个操作,要么全部执行,要么全部不执行(执行的过程中是不会被任何因素打断的)。
可见性
一个线程对共享变量的修改,能够被其他线程看到。通过 volatile 关键字、锁(如 synchronized)来实现可见性。
有序性
程序的执行在实际运行时可能会被重排序,但JMM提供了一定的保证,使得某些操作在多线程环境中会按照程序的顺序执行。
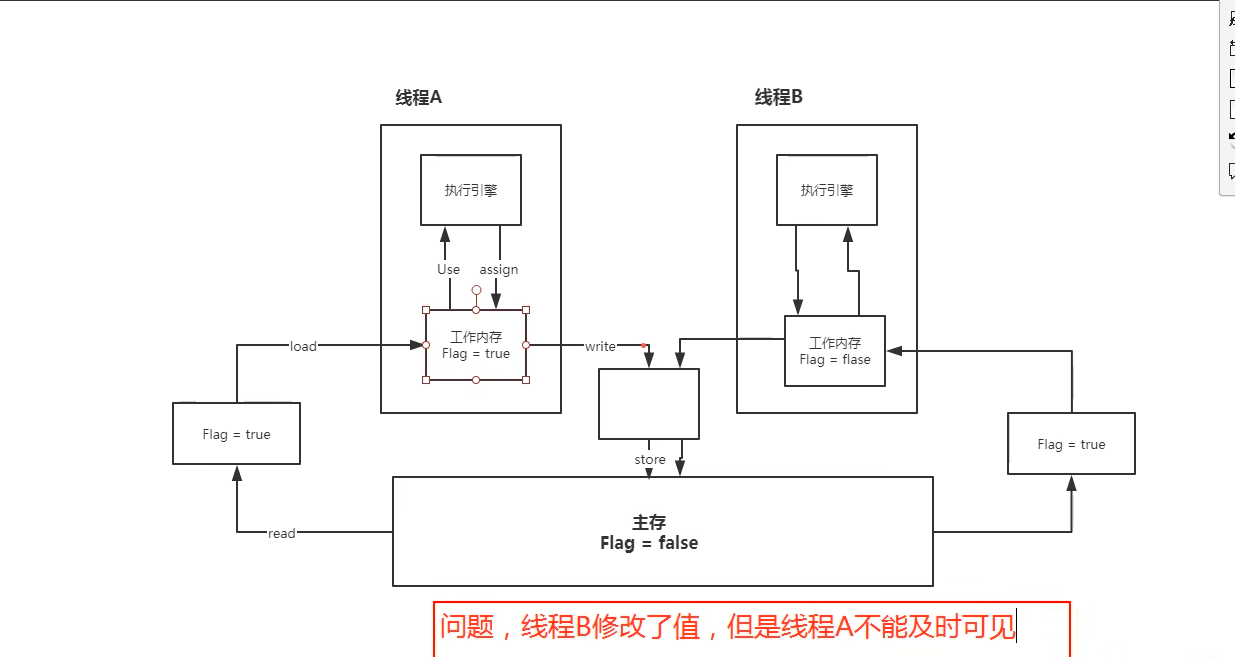
JMM中的八种操作
JMM抽象了线程和主内存之间的关系,定义了以下八种操作来完成主内存和工作内存之间的交互:
• lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占状态。
• unlock(解锁):作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
• read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用。
• load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
• use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
• assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
• store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
• write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
Java内存模型还规定了执行上述8种基本操作时必须满足如下规则:
不允许read和load、store和write操作之一单独出现,以上两个操作必须按顺序执行,但没有保证必须连续执行,也就是说,read与load之间、store与write之间是可插入其他指令的。
不允许一个线程丢弃它的最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。
不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中。
一个新的变量只能从主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,换句话说就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作。
一个变量在同一个时刻只允许一条线程对其执行lock操作,但lock操作可以被同一个条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。
如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值。
如果一个变量实现没有被lock操作锁定,则不允许对它执行unlock操作,也不允许去unlock一个被其他线程锁定的变量。
对一个变量执行unlock操作之前,必须先把此变量同步回主内存(执行store和write操作)。
Happens-before 规则
JMM还定义了一个重要的概念:happens-before,它是判断数据是否存在竞争、线程是否安全的依据。happens-before原则规定了以下几种情况:
• 程序次序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
• 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
• volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
• 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
• start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作。
• join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
• 中断规则:对线程interrupt()方法的调用happens-before于被中断线程的代码检测到中断事件的发生。
• 终结器规则:对象的构造函数执行、结束happens-before于它的finalize()方法的开始。
JMM在保证有序性时所使用的两个原则:
* as-if-seria(单线程遵循):在单线程中,无论如何重排序,程序执行的结果都应该与代码顺序执行的结果一致(java编译器和处理器运行时都会保证在单线程中遵循as-if-serial规则,多线程存在程序交错执行时,则不遵守)
* happens-before(多线程遵循):在发生操作B之前,操作A产生的影响都能被操作B观察到,“影响”包括修改了内存中共享变量的值、发送了消息、调用了方法等,它与时间上的先后发生基本没有太大关系。这个是多线程中程序运行遵守的原则,保证在多线程环境下程序运行结果不会出错,后面有对其的详细讲解。重排序也就是遵守这个原则。
JMM保证三大特性:原子性、可见性、有序性。
JMM对原子性的保证方式:
Synchronized:同步代码块
JUC中Lock的lock:加锁
使用原子类
JMM对可见性的保证方式:
volatile:在JMM模型上实现MESI协议,也就是在变量使用volatile关键字,一个线程将内存中的有volatile关键字标识的变量拿到工作空间进行修改后,就会通知其他线程再访问这个变量的话直接到内存中去找,就不要在自己的工作空间找了,因为数据已经被修改了。
深入来说,是通过加入内存屏障和禁止重排序优化来实现的:
对volatile变量执行写操作时,会在写操作后加入一条store屏障指令,会将cup数据强制刷新到主内存中去
对volatile变量执行读操作时,会在读操作前加入一条load屏障指令,强制缓存器中的缓存失效,每次使用都要去主内存中重新获取数据
通俗地讲,volatile变量在每次被访问的时候,都强迫从主内存中读取该变量的值,而当该变量在发生变化时,又会强迫变量讲最新的值刷新到主内存中,这样,任意时刻,不同的线程总能看到该变量的最新值。
synchronized:使用synchronized加锁来保证可见性,它会保证两条原则:
线程解锁前,必须把共享变量的最新值刷新到主内存中
线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新值(注意:加锁与解锁需要是同一把锁
JUC中Lock的lock
JMM对有序性的保证方式:
volatile:被加了volatile关键字的变量不会被重排序。
对于volatile修饰的变量:
volatile之前的代码不能调整到它的后面
volatile之后的代码不能调整到它的前面
霸道(位置不变化)volatile实现可见性的硬件基础就是cache line
synchronized:被它括起来的代码块内部会进行重排序,但是同步代码块整体在所有代码中的顺序不会改变。
对synchronized同步代码块:
同步代码块之前的代码不能调到它后面
同步代码块之后的代码不能调到它前面
JMM对有序保证按照Happens-before原则:
程序次序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作
管程锁定规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。同步块中线程安全。
volatile变量规则:对一个volatile变量的写操作happens-before对这个变量的读操作。
线程启动规则:Thread.start() happens before 所有操作。
传递性:如果A happens-before B,且B happens-before C,那么A happens-before C
线程终止规则:线程中所有操作都happens-before对此线程的终止检测。
对象finalize规则:一个对象的初始化完成(构造函数执行结束)先行于发生它的finalize()方法的开始
程序中断规则:对线程interrupted()方法的调用先行于被中断线程的代码检测到中断时间的发生。
满足任意一个原则,对于读写共享变量来说,就是线程安全。
时间上的先后与happens-before的关系:
一个操作时间上先发生于另一个操作“并不代表”一个操作happen—before另一个操作。
一个操作happen—before另一个操作“并不代表”一个操作时间上先发生于另一个操作。
volatile
详解 volatile
volatile 是 Java 中的一个关键字,用于修饰变量,具有以下特性:
保证可见性:对
volatile变量的写操作会立即被其他线程可见,保证了多线程之间对变量的可见性。不保证原子性:
volatile修饰的变量并不能保证多线程并发操作的原子性,需要配合其他机制(如锁或原子类)来保证原子操作。禁止指令重排:
volatile变量的读写操作会禁止指令重排,保证了操作的有序性。
保证可见性
volatile 修饰的变量在多线程环境下,对该变量的写操作会立即被其他线程可见,从而保证了多线程之间对变量的可见性。这是因为 volatile 变量的写操作会强制将修改后的值立即刷新到主内存,而读操作会从主内存中获取最新的值。
不保证原子性
volatile 修饰的变量并不能保证多线程并发操作的原子性,例如对 volatile int count 进行自增操作 count++,这个操作并不是原子的,需要通过其他机制(如锁或原子类)来保证原子操作。
禁止指令重排
volatile 变量的读写操作会禁止指令重排,保证了操作的有序性。这意味着在多线程环境下,对 volatile 变量的读写操作不会被重排序,保证了操作的有序性。
实例代码
public class VolatileExample {
private volatile boolean flag = false;
public void writer() {
flag = true; // 写操作
}
public void reader() {
while (!flag) {
// 读操作
}
System.out.println("Flag is now true");
}
public static void main(String[] args) {
VolatileExample example = new VolatileExample();
Thread writerThread = new Thread(() -> example.writer());
Thread readerThread = new Thread(() -> example.reader());
writerThread.start();
readerThread.start();
}
}
在这个示例中,flag 变量被声明为 volatile,在 writer 方法中对 flag 进行写操作,而在 reader 方法中进行读操作。由于 flag 是 volatile 变量,写操作会立即被其他线程可见,保证了可见性。
Comments